(This is something of a continuation of this post: https://defining-computers.blogspot.com/2019/05/analyzing-mechanized-trust.html.)
So you have friends who recommend Libre/Free/Open Source software like the GIMP or Libre Office, but you aren't sure how to get it. So you type "How do I get GIMP" or "download gimp" into your web browser's search box and hit return and it shows you a bunch of different advice.
In the case of the GIMP, gimp.org shows up pretty high in the results page. Likewise Libre Office and libreoffice.org. And your friends and I say these are the official sites, so you have some pretty high levels of confidence you know what to do.
But if you look down the list a bit you see download.cnet.com. Aren't they bigger? Shouldn't you trust them more? Or you see something like imagecustomize.com, and for some reason you think that name makes more sense than "the GIMP".
Most of the major libre projects will have URLs based on their project name, and, with libre software, the project's own website is where you want to go to get it. Otherwise, you risk getting something that has been tampered with and compromised and could easily compromise your computer.
Okay, you know that. So you go to the project sites and find the download pages and click the download link or button and your browser kicks up a fit:
***** DANGER DANGER!!! NOT MICROSOFT APPROVED!!! *****
Of course not, you chuckle.
Wait. Yes, of course not. But hold off a moment. Even so, there may be some meaning to that.
Mouse around the website a bit. Find the instructions for installing and using the software. Find the mailing list for user support. Read a few posts. Get a feel for the community. See if you feel comfortable about the attitude of the developers and the community.
If you're planning on using software, whether you buy the "traditional" kind or download the libre kind, you want to be sure you can ask questions and get answers.
(In truth, the traditional way of "Pay me and trust me!" makes no more sense to me than the libre way of "Use my stuff and if it helps you donate to the project so we can keep making it." If anything, it seems like the libre way should be the usual way, not the pay-and-trust way.)
Anyway, spend a few hours or days or more getting used to the community. Not only does it help you decide whether you trust the community enough to download and use their software, it also helps you recognize the community, in case you get mail claiming to be from the community but telling you strange things.
So, the time to download and install has come, but you might download the software and try to install it, and find your anti-virus/anti-malware program blocking you at some inconvenient point.
***** DANGER DANGER WARNING WARNING *****
***** MIGHT DO STRANGE THINGS TO YOUR COMPUTER!!! *****
Had something like this come up on the mailing list for the GIMP just now:
> Report from Trend Micro antivirus during download:
>
> Time: 11/11/2021 16:36
> File: gimp-2.20.28-setup.exe-part
> Threat: TSPY.Win32.TRX.XXPE50FSX016E0002
> Action: Quarantined
Putting quotes around that and doing a web search yields no results. If Trend Micro has a specific record for this, they haven't published it, or it's really new.
Best thing to do is contact them and see if they are willing to share what they have, but this report is similar to one on the mailing list for the language Go:
https://github.com/golang/go/issues/45191
You'll note the phrase "out of an abundance of caution". I'm afraid I would use other words, such as "laziness", but I don't know if that would or should put your mind at ease. You probably don't know me from Adam.
So, I finally get to the purpose of this rant. I'll tell you what I go through when I prepare to install free/libre software. Read through it once before you try following along:
(1) Do I trust the developer(s)?
I've talked around this above. If I don't trust them, I don't even try to download their software. I go looking for another alternative.
In the case of the GIMP and Libre Office, I've been watching the community and using the software long enough to trust the developers enough to install it on a new computer if i think it hasn't been tampered with.
(2) So it comes down to detecting tampering.
(2a) Is the download available on HTTPS servers?
The URLs for the website for downloading the GIMP start with HTTPS, starting from here:
https://www.gimp.org/downloads/
If you want it for Mac or MSWindows and it doesn't automagically show you the one for your OS, there's a link or button you can click on to get there.
If you want it for Ubuntu or Debian or some other Linux, or from one of the BSDs, you can probably get it from the packages for your OS, and you won't need these instructions. (There are other instructions for less well-known software and less well-known OSses, but this isn't the place.)
HTTPS (as opposed to unencrypted HTTP) gives a fairly high degree of confidence that the owners and operators of the web site is who they say they are, and that what you download makes it to your computer safely. For many people it's enough. For me, it helps.
In addition, if you have a torrent client, they may provide a link for torrent download. Torrent download is a bit more secure than simple download, for what it's worth. It's also supposed to use spare bandwidth instead of prime, and so be friendlier to the Internet.
(2b) Do they make checksums available?
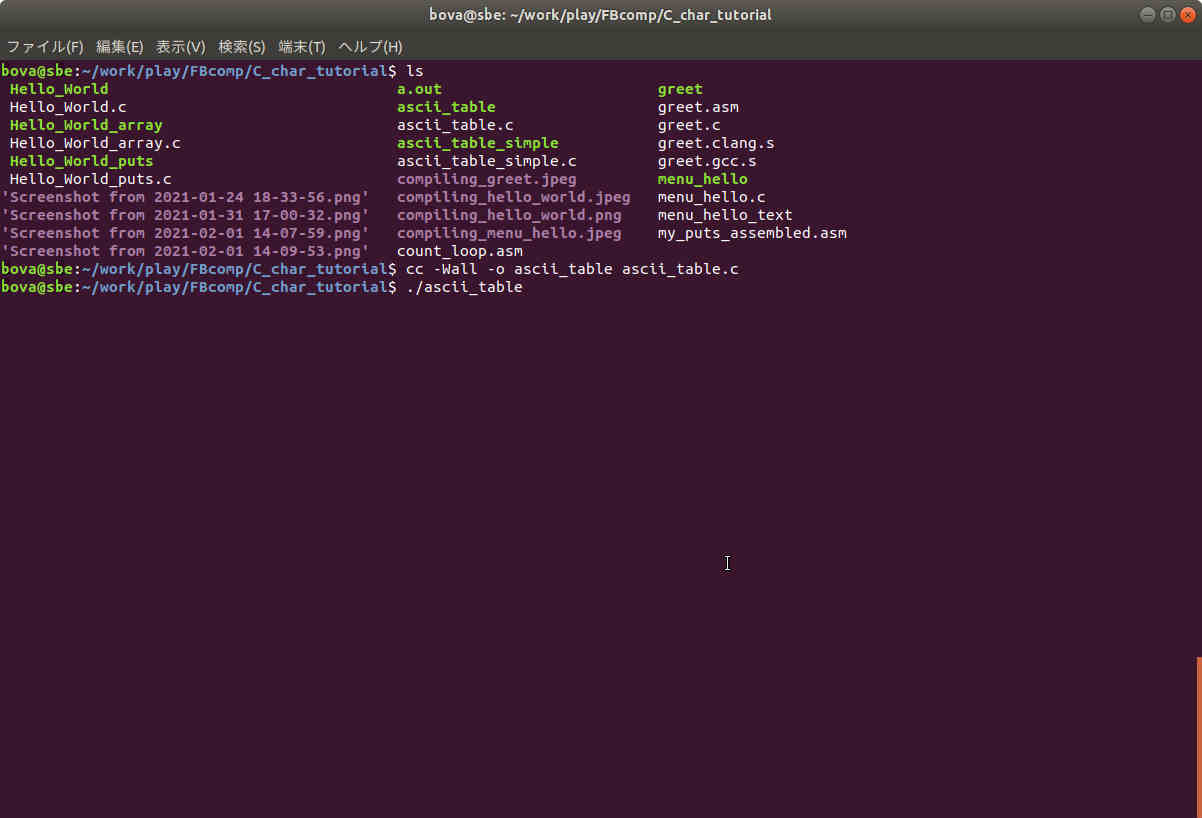
The GIMP makes checksums available, publishing the checksum for the MSWIndows download on the download page underneath the download buttons. If you've wandered around enough, you've probably seen it. But you may not have recognized it.
As I write this, the current SHA256 checksum for the GIMP is
2c2e081ce541682be1abdd8bc6df13768ad9482d68000b4a7a60c764d6cec74e
You can use the certutil.exe utility in MSWindows to check that from a shell or powershell window. The command is
certutil -hashfile filename SHA256
Substitute the name of the file for "filename", of course. In the case of the present version of the GIMP, it's "gimp-2.10.28-setup.exe".
Also, make sure you are in the download directory before you issue the command.
Below the checksum, the GIMP site gives a link to VirusTotal, which you can use to check whether vendors are blacklisting this particular checksum. Some other projects also do.
But if you do that, copy the entire checksum and use your search engine to go direct to VirusTotal and paste the checksum in. That way, in the very slight chance that you are seeing a spoof of the GIMP's website, you can avoid the possibility of jumping to a spoofed VirusTotal, as well.
I'm not sure how useful that information will be, but some may find it useful.
Speaking of man-in-the-middle, If you're worried that, in spite of the site using HTTPS, the download page is being spoofed by a man-in-the-middle and the checksum is faked, there is a way to get some confidence that is not the case.
Look around the download page or the installation instruction pages and the link to the mirrors. Look through the list of mirrors and pick one at random.
I happen to be familiar with the XMission mirror in the US, so I'll use that as an example. Search the web for XMission and note the URL. Open the site and copy the domain name:
https://xmission.com
Use right-click to copy (don't jump to) the link in the mirrors list:
https://mirrors.xmission.com/
Note that the xmission.com domain name is the same. Now you can paste the mirroring subdomain name into the URL blank of your browser and go to their libre downloads section and be pretty sure you're safe from everything but guess-ahead DNS poisoning.I'm deliberately refraining from making those links active. If you
are worried about man-in-the-middle attacks, you should not trust active
links on my blog. I might make them appear to take you to the right
place but take you someplace else, instead.
Drill down into the gimp section, into the gimp section of that, into the current version (2.10) and into the windows section of that. For the XMission mirror, the URL you end up at is (currently)
https://mirrors.xmission.com/gimp/gimp/v2.10/windows/
From there, you can download the SHA256SUMS file, save it on your computer, open it with a text editor, and look at the line for the version you downloaded. If the default text editor (probably Notepad) shows the lines without breaks, try the other one (WordPad).
In the case of the GIMP v. 2.10.28, the line you're looking for would be the line for gimp-2.10.28-setup.exe (currently the last line).
Copy the checksum from the web page and paste it below that line like this:
2c2e081ce541682be1abdd8bc6df13768ad9482d68000b4a7a60c764d6cec74e gimp-2.10.28-setup.exe
2c2e081ce541682be1abdd8bc6df13768ad9482d68000b4a7a60c764d6cec74e
and you can visually check that the checksums are the same.
If you need even more assurance, try one or two more mirrors, and you have two or three witnesses that the checksum is the one the project publishes.
To recap, what I've walked you through is a way to get more than one witness that you got what the GIMP project put up there for you, which, if you trust the project, should be enough to trust the download, even if random security vendor is too lazy to be sure that it isn't giving false positives on free/libre software.
You can use the same sort of process with Libre Office and many other Free/Libre/Open Source projects, including Debian OS and Ubuntu OS (although Ubuntu's website and mirrors sometimes make the checksums hard to find).
In LibreOffice's case, below the download link you'll find a link for the torrent, and beside that, a link for info. Clicking on the info link will show you the checksums and list of mirrors. Oh -- A hash is a checksum, so look for the hashes.
For the mirrors for LibreOffice, I go down the list of mirrors and pick KDDIlabs since I'm sort of familiar with them, and right-click copy the link, then paste it into an open text editor window. I grab the top part of it, https://ftp-srv2.kddilabs.jp/, and copy-paste it to a browser window's URL blank. And I can drill down from there into office, tdf, libreoffice, stable, 7.2.2, win, x86_64, and, oh dear. No checksum files.
-----
LibreOffice developers are not believers in the many witnesses approach. I'll need to have gnupg and find the signature keys, instead. Some people think that is a better approach, but it does leave you with a chicken-and-egg conundrum. I'll have to finish this part of this post later, I've just run out of time this weekend.
The safest thing to do in this case is, if you have a friend who has a Linux or BSD OS running, have your friend install gnupg on her system, set it up to recognize the keys for libreoffice, download the libreoffice installer, and check the signatures, and then put it on a USB drive for you. Or, you could back up a bit, and have her do the same for the MSWIndows version of gnupg, which you could install and set up on your computer, and then you're set to check fingerprints instead of or along with checksums.
-----
As I mentioned above, if you are using Debian or Cygwin, et. al., the OS project has packages for all the major libre programs, and you can use the OS's package manager directly, and the package manager handles all the checksum checking for you. Which means you only need to do the above running around the web for multiple witnesses once, when you first download the OS.
(Some OSses make upgrading to a new version of the OS as straightforward as getting a package, but some do not. In the latter case, you may end up looking for around for multiple witnesses on the checksum on every OS upgrade, but that isn't very often.)
Some projects (last time I installed Cygwin) do not make checksums available on their mirror sites. I'm not sure why; it may have something to do with the rate of updates and the way they handle download and updates. Cygwin, in particular, is more like the OSses, with its own package manager.
Now that I've walked you through the process, you have no excuse not to try Libre software, right?
Heh. I know, it's scary. But reading through this again in a few weeks or months should help.