[TOC]
Continuing with the idea of greeting to further extend our beachhead, let's say we want the computer to give the user a list of people to greet, and let the user choose who gets greeted from that.
Hold on to your hat, this is a significantly longer and more involved
program.
/* Extending the Hello World! greeting beachhead --
** Let the user choose from a list whom the computer should greet.
** This instance the work of Joel Rees.
** Copyright 2021 Joel Matthew Rees.
** Permission granted to modify, compile, and run
** for personal and educational use.
*/
#include <stdio.h>
#include <stdlib.h>
#include <ctype.h>
#define MENU_CT 10
#define MENU_ITEM_LN 12
char menu[ MENU_CT ][ MENU_ITEM_LN + 1 ] =
{
"Johnny",
"Ginnie",
"Marion",
"Deborah Ann",
"Howard",
"Joe",
"Robin",
"Dawn",
"Cornelia Maxi", /* <= Look closely at this! */
"Nina"
};
void my_puts( char string[] ) /* What's different this time? */
{
int i;
for ( i = 0; string[ i ] != '\0'; ++i )
{
putchar( string[ i ] );
}
putchar( '\n' );
}
/* Convert a number from zero to nine to a digit character. */
int textdigit( int n )
{
return n + '0'; /* A trick of ASCII encoding! */
}
/* Convert a number to a text digit and put it on the output device. */
void putdigit( int n )
{
putchar( textdigit( n ) );
}
int main( int argc, char * argv[] )
{
int i;
int ch;
my_puts( "From among" );
for ( i = 0; i < MENU_CT; ++i )
{
putchar( '\t' ); putdigit ( i ); putchar( ':' );
putchar( ' ' ); my_puts( menu[i] );
}
my_puts( "Whom should I greet?" );
ch = getchar();
while ( !isdigit( ch ) )
{
putchar( ch ); putchar( '?' );
fputs( "Please enter a number from 0 to ", stdout ); putdigit( MENU_CT - 1 );
my_puts( ":" ); /* <= Why do I do it this way? */
ch = getchar();
}
fputs( "Oh-kay, ", stdout ); putchar( ch ); my_puts( "." );
putchar( '\n' ); putchar( '\n' ); putchar( '\n' ); putchar( '\n' );
fputs( "Hal-looooooooooooo ", stdout );
my_puts( menu[ ch - '0' ] );
}
Copy/paste that into your favorite text editor window, or at least one you're comfortable with, and keep it open where you can reference it, and let's work through it.
This program references the ctype library. This library allows you to
check characters in the ASCII range, to determine such things as whether they
are digits, punctuation, space, etc. It is where get isdigit(), which
we use to check the menu selection, so we #include the header.
#define gives you one way to define constants. For many pre-ANSI compilers, #define constants are the only constants. We'll return to #define later to discuss the differences between macros and constants, but, for now, that's what I use it for here, defining the constant count of menu items, MENU_CT, and the constant maximum number of characters in each, MENU_ITEM_LN.
menu[][] is a two-dimensional array of characters, whose size is defined by the above #define constants, MENU_CT, and MENU_ITEM_LN. And it is a true two-dimensional array, allocating MENU_CT times (MENU_ITEM_LN + 1) bytes of memory space.
I just had to bring our my_puts() function in for sentimental reasons.
Or, maybe, so I could show a different way to declare its
string parameter. It will be useful to stop and compare this definition
with the
last one, before continuing.
You may by now be asking about the difference between
char * string;
and
char string[];
You may, you know. It's a good thing to ask about.
Well, when declaring string as a parameter to a function, there isn't any effective difference.
If we were declaring string as, say, a global variable, there would be
an important difference, but let's not distract ourselves with that just yet.
We have too much ground to cover first.
Moving on, for the moment, let's just assume that textdigit() and putdigit() do what their names imply and the comments say, the one converting a number to a digit character, and the other putting a number on the output device. I'll explain pretty soon. I promise.
(I think the ASCII trick will work for the digits in EBCDIC, as well. I'll have to test it sometime.)
Skipping forward to the main() function, the following lines declare two integer variables called i and ch:
int i;
int ch;
Maybe we need to go on a long detour, here.
------ Side Note on Integers ------
These are not the ideal integers of mathematics that extend in range both directions to infinity. Variables in computers have limited range. (You could say integer variables provide the basis for implementing certain types of a mathematical concept called a ring, but let's not go there today. I'll get there, too, eventually.)
On a sixteen-bit CPU, they will (probably) have a range of
(-215 .. 215 - 1)
or from -32,768 to 32,767.
On a modern 32-bit CPU, the range will probably be
(-231 .. 231 - 1)
or from -2,147,483,648 to 2,147,483,647.
(Yes, I am an American, and I use the comma to group columns in numbers. If
you are from a country where they use something different, please make the
substitution. You can let me know about it in the comments. And, by the way,
there are ways to deal with that in standard C libraries. Sort-of.)
On a modern 64-bit CPU, int variables may be 32-bit integers or they
may be 64-bit integers, depending on how the compiler architect interprets the
CPU resources and whether the sales managers insist on coddling past
programmers who hard-wired 32-bit integers into their programs. Or (more
likely) depending on compiler switches.
If int is a 64-bit integer, i and ch will be able to take
the range
(-263 .. 263 - 1)
or from -9,223,372,036,854,775,808 to 9,223,372,036,854,775,807. Nice big
numbers. Pretty close to minus and plus infinity, from a practical point of
view.
Now, we're not using even the full range of 8-bit integers, so we could have
declared them as short int, or even as char in this program.
But, why?
Oh. Wait. Before that, why, you ask, is ch, which sounds like it's going to be a character, declared as an int?
Excellent question. I'll tell you about EOF later, but, for now, I'll just say it's a convention, and it's a good programming habit to make sure your integer variables will always have enough space to hold their values. Remember, char is an integer type, and a sub-range of int, usually a proper sub-range.
Are you interested in the range that char can take on, since I insist
it's an integer type? For the usual size of char,
- signed char: (-27 .. 27 - 1), or -128 to 127.
- unsigned char: (0 .. 28 - 1), or 0 to 255.
------ End of Side Note on Integers ------
Back to the program. You've seen the for loop before, in my_puts(), but I haven't explained it.
Hmm. Before I explain the for loop, I should explain the while loop.
Loops are conditional constructs, much like the if selection construct.
But, not only do they branch around code, they repeatedly run through code. Of
course they repeat. That's why they're called loops.
It's a common misconception, but, as I said previously, conditionals are not functions. In C, they require parenthesis for the condition expression, but what is inside is a set of conditions, rather than parameters.
Also, the if, while, for, and do ... while conditionals never have return values in C.
And, as I have mentioned, they don't have to have curly brace-enclosed blocks if they only apply to a single statement. But it is usually wiser and less confusing to give them explicit blocks anyway. You often find that you actually wanted more than one statement under the conditional part.
I'm dancing around what a loop is because I don't want to show you the accursed goto. And I don't want to do more hand-compiled assembly language. So, let's look at a theoretical example loop, instead:start( music );
while ( music_is_playing( party ) )
dance();
This is going to invite more confusion, I just know it.
The dancing doesn't stop immediately when the music stops. The loop checks
that the music is playing, and then the program dances for a bit. Then it
checks again, and then it dances some more. That's the way software works.
(This is very important to remember. Many expensive commercial projects have
met disaster because a programmer forget that conditionals are not constantly
monitored.)
Let's look at another example:
fill( plate );
while ( food_remains( plate ) )
{
eat_a_bite( rice );
eat_a_bite( sashimi );
eat_a_bite( pickled_ginger );
eat_a_leaf( shiso );
eat_a_bite( nattō );
eat_a_bite( pickled_radish );
}
And the way this is constructed, once we take that first bite of rice in the
loop, we will continue on through the sashimi, all the way through the
bite of pickled radish, before checking again whether there is food on the
plate. (There is a way to break the loop between bites. And there is
concurrent execution, which .... Again, later.)
while loops test their condition before entry, so the condition must be prepared -- primed. That's what fill( plate ) and start( music ) do above.
The for loop primes itself.
There is a do ... while () loop where you jump in before testing, but
it turns out to be not very useful. I'll explain why later.
We need something concrete to look at before we fall asleep. Computers are good at counting, we hear. Let's try a counting loop:
count = 0;
while ( count < 100000 ) count = count + 1;
/* Only one statement, no need for braces. Note that trailing semicolon. */
Note that, since 100,000 won't fit in 16 bits, the count variable must be declared to be one of the 32-bit types for the CPU and compiler.
I'd (cough) like to show you how that would look in 6809 assembly language,
but the 6809 needs lots of extra instructions to do 32-bit math, and the extra
instructions would cloud the issues. So I'll use 68000 assembly language. It
looks different, but my comments should clear things up.
; Uses 32 bit .Long instructions.
* count = 0;
MOVEQ #0,D7 ; Compiler conveniently put count in D7.
* while ( count < 100000 )
_wb_0000
CMP.L #100000,D7 ; Compare -- subtract 100000 from D7,
; but don't store result.
BGE _we_0000 ; Branch over increment and loop end
; if D7 is greater than or equal to 100,000.
* count = count + 1;
ADD.L #1,D7 ; Add 1 to D7.
BRA _wb_0000 ; Branch always back to beginning of loop.
_we_0000
; Code continues here.
(That's fairly well optimized object code. But there is one further
optimization to make which would be confusing, so I won't make it. It's also
hand-compiled and untested. But it's fairly understandable this way.)
This is a good way to make the computer waste a little time. On the venerable 6809, it would take about a second or so. On the 68000 at mid-1980s speeds, it would take between a fifth and a tenth of a second. On modern CPUs, it would take something in the range of a millisecond, if that. Just a little time.
And the count stops at 100,000.
------ Side Note on Incrementing ------
Adding one to a count happens so much in programs that C has a nice shorthand for it:
++count;
is the same as
count = count + 1;
Incrementing by other than 1 has a shorthand, as well, and sometimes you want
to increment a value after you use it instead of before. We'll look at that
later, too.
------ End of Side Note on Incrementing ------
Let's remake that counting loop as a for loop:
for ( count = 0; count < 100000; ++count ) /* Loop body looks empty. */ ;
Notice that there is nothing between the end of the condition expression and
the semicolon except for a comment for humans to read and notice that the
space is intentionally left blank.
That's an example of an empty loop.
In a sense, it isn't really completely empty, because the loop statement
itself contains the counting, in addition to the testing. But, again, the only
effect you notice is a small bit of time wasted, and count ends at
100000. (Some compilers will helpfully optimize such loops completely out of
the program and just set count to 100,000 -- unless you tell them not
to because you know you want to waste the computer's time.)
Empty loops have a significant disadvantage. They are easy to misread. If you have some reason to use an empty loop, use a comment to make it clear, and I recommend giving it a full empty block, just to make it really clear:
for ( count = 0; count < 100000; ++count ) { /* Empty loop! */ }
This for loop is exactly equivalent to the while loop above,
plus the statement priming the count. And the code output will be the
same, as well.
One final note of clarification, if we want a counting loop that prints the count out, the for version of the loop might look something like this:
for ( count = 0; count < 100; ++count )
printf( "%d\n", count );
And this for loop is exactly identical to the following primed
while loop:
count = 0;
while ( count < 100 )
{
printf( "%d\n", count );
++count;
}
We'll be looking more at loops (and printf()) later, but that should be enough to continue with reading my_puts().
It declares a char array, string, as its only parameter.
In early C, we definitely did not want to copy whole arrays. It took a lot of
precious processor time and memory space. So the authors of C decided that an
array parameter would be treated the same as a pointer to its first
element.
Arrays still usually aren't something you want to make lots of copies of, so
this design optimization might not be a bad thing, even in our current world
where RAM and processor cycles are cheap. But it does invite confusion, since
both a pointer and an array can be modified by the indexing operator.
Specifically, given
char ch_array [ 10 ] = "A string";
char * ch_ptr stringB = "B string";
in 6809 assembler we would see something like this:
ch_array FCC "A string"
FCB 0
_s00019 FCC "B string"
FCB 0
ch_ptr FDB _s00019
so you see that "B string" is stored in an array with one of those odd names that won't be visible in the C source -- thus, anonymous, and ch_ptr is a pointer that is initialized to point to the anonymous string. On the other hand, "A string" is stored directly under the name ch_array, which is very much visible in the C source.
However, unless we overwrite ch_ptr with some other pointer,
ch_array[ 0 ] points to 'A',
ch_ptr[ 0 ] points to 'B' and
ch_array[ 3 ] and ch_ptr[ 3 ] both point to (different) 't's.
This leads to headaches if you aren't careful, but it also means that my_puts() is quite readable. Take the char array that gets passed in and count up it, looking at each char and putting it out on the output device as we count -- until we reach a 0. And the way the test is arranged, it will see that the char is 0 and stop before outputting it.
I'm going to present both 6809 compiler output and 68000 compiler output. Both are very much not optimized and not tested, but you can read my comments and see how the thing fits together.
6809 first:
* void my_puts( char * string )
_my_puts_6809
* {
* int i;
LEAU -2,U ; Allocate i.
*
* for ( i = 0; string[ i ] != '\0'; ++i )
LDD #0 ; Initialize i.
STD ,U
_my_puts_loop_beginning
; Split stack, no return PC to avoid.
LDX 2,U ; Get string pointer.
LDD ,U ; Get i.
LDB D,X ; Get string[ i ] (destroying i!)
; LDB will see 0 for us, no CMP necessary,
; but let's refrain from confusing optimizations.
CMPB #0 ; Is this char 0?
BEQ _my_puts_loop_end
* {
* putchar( string[ i ] );
; Even simple optimization would not repeat this.
LDX 2,U ; Get string pointer.
LDD ,U ; Get i.
LDB D,X ; Get string[ i ] (destroying i!)
CLRA ; It was unsigned, extend it to 16 bits.
PSHU D ; Push the parameter for putchar().
JSR _putchar ; Call putchar().
* }
LDD ,U ; Increment i.
ADDD #1
STD ,U
; Go back for more.
BRA _my_puts_loop_beginning
_my_puts_loop_end
* putchar( '\n' );
LDD #_C_NEWLINE
PSHU D
JSR _putchar
* }
RTS
Now 68000:
* void my_puts( char * string )
_my_puts_68000
; The compiler has been told to use 32-bit int .
* {
* int i;
; The compiler will conveniently put i in D7.
*
* for ( i = 0; string[ i ] != '\0'; ++i )
MOVEQ #0,D7 ; Initialize i.
_my_puts_loop_beginning
; Split stack, no return PC to avoid.
MOVE.L (A6),A0 ; Get string pointer.
MOVE.B (D7,A6),D0 ; Get string[ i ]
; MOVE.B will see 0 for us, no CMP necessary,
; but let's refrain from confusing optimizations.
CMP.B #0,D0 ; Is this char 0?
BEQ _my_puts_loop_end
* {
* putchar( string[ i ] );
MOVEQ #0,D0 ; Avoid need to extend char to int .
MOVE.B (D7,A6),D0 ; Get string[ i ]
MOVE.L D0,-(A6) ; Push the parameter for putchar().
JSR _putchar ; Call putchar().
* }
ADD.L #1,D7 ; Increment i.
; Go back for more.
BRA _my_puts_loop_beginning
_my_puts_loop_end
* putchar( '\n' );
MOVEQ #_C_NEWLINE,D0
MOVE.L D0,-(A6) ; Push the parameter for putchar().
JSR _putchar
* }
RTS
The reason I give some (hand-)compiled output is to help motivate the idea that C programs are (effectively) performed step-by-step in the order that the source code dictates. This includes the test conditions in conditional constructs. It's part of the rules of the game for C, even though other languages do something different.
Those languages have rules, as well. Without the promise of order that the
rules give, programs would not function.
(Optimization can break this promise, however. More later.)
To understand textdigit(), we need to look at an ASCII chart, or at
least the part where the numbers are:
| Code (decimal) | Character |
|---|---|
| 47 | / |
| 48 | 0 |
| 49 | 1 |
| 50 | 2 |
| 51 | 3 |
| 52 | 4 |
| 53 | 5 |
| 54 | 6 |
| 55 | 7 |
| 56 | 8 |
| 57 | 9 |
| 58 | : |
Characters are represented by codes inside the computer, and the codes are
numbers -- integers, to be specific. You can add numbers to these integers,
and the result may be a different character. (Or it may not fall within the
table, depending on the number, but we won't worry about that.)
So, if we start with a number from 0 to 9 in the parameter n and we add the code for the character '0' to it, we get a new code for the character version of the number that was in n.
The addition may be more clear if we show the codes in hexadecimal:
| Code (decimal) | Code (hexadecimal) | Character |
|---|---|---|
| 47 | 2F | / |
| 48 | 30 | 0 |
| 49 | 31 | 1 |
| 50 | 32 | 2 |
| 51 | 33 | 3 |
| 52 | 34 | 4 |
| 53 | 35 | 5 |
| 54 | 36 | 6 |
| 55 | 37 | 7 |
| 56 | 38 | 8 |
| 57 | 39 | 9 |
| 58 | 3A | : |
And then we return the resulting character.
I'd show the assembly language for this, but it's dead simple. On the 6809, convention will have the compiler load the return value in register D before executing the return from subroutine. On the 68000, it will probably be loaded into D0. Other CPUs will have similar conventions for where to put the return value. There may be better ways, but this is the usual way now.
The putdigit() routine is essentially just semantic sugar. I hope it makes the program easier to understand. It just uses textdigit() to convert the number to a character and use putchar() to put it on the output device.
That brings us back to main().
The first loop in main() is a for loop, and it formats and prints out the menu array, along with using putdigit() to put out numbers for selecting a name from the menu array.
By keeping the number of menu items to ten or less, we can use our simplified output routines. We'll show how to deal with more later.
The second loop in main is a while loop, and its purpose is to read characters from the input, and complain and discard them if they are not numbers, until it gets a number.
My odd choice of which routines to use where has something to do with giving you a reason to read through the source in my_puts(), and also something to do with output buffering. (my_puts() forces the output buffer to be flushed with the newline it puts out. Otherwise, we would have no guarantee that the characters we are putting out make it to the screen in time to tell the user what we want to tell him or her. This is something else we will look at later.)
I think the rest of main() is understandable at this point.
Hopefully, you've seen what the bug I planted in the menu does by now. It has to do with allocating enough room for trailing NULs for strings. I'll leave the fix as an exercise, for now.
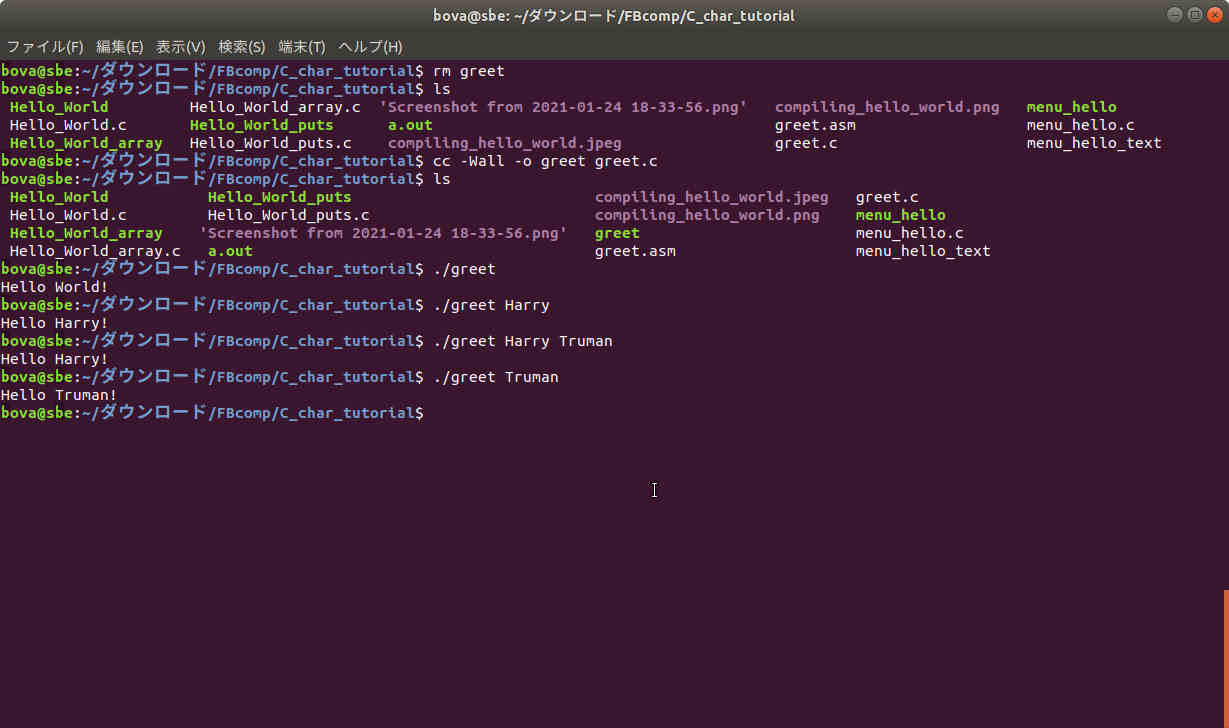
Here's the screenshot:
How long it will take to get the next step up, I don't know. I keep taking on too many projects.
In the meantime, play with what you've learned so far. Fix the bug, or course. Experiment and explore.
The next one is ready sooner than I expected. I decided to show you how to get an overview of the ASCII characters.
[TOC]