[TOC]
Let's set Hello World! aside for a while.
In the last project, we needed to look at a part of the ASCII table to explain the code for the menu selections. I happen to have that part of the table mostly memorized, and I know about the ASCII man page in modern *nix OSses, so I just built the code by hand. But it would be nice to have our own ASCII chart, and it would be cool to let the computer build it for us, right?
Let's give it a try.
First, we'll build a simple ASCII table. I don't have the control code mnemonics completely memorized, so we'll go to Wikipedia's ASCII page and the *nix manual pages mentioned above for reference.
man ascii
(Using the terminal window's copy function, I pasted the manual page contents into an empty gedit text document window, and used gedit's regular expression search-and-replace to extract the parts I wanted. Very convenient, once you get the hang of it.)
With a little bit of work (a very little bit), I came up with the following
simple table generator:
/* A simple program to print the ASCII chart,
** as part of a tutorial introduction to C.
** This instance the work of Joel Rees,
** Whatever is innovative is copyright 2021, Joel Matthew Rees.
** Permission granted to modify, compile, and run
** for personal and educational uses.
*/
#include <stdio.h>
#include <stdlib.h>
/* reference:
== *nix man command: man ascii
== Also, wikipedia: https://en.wikipedia.org/wiki/ASCII
*/
char *ctrl_code[33] =
{
"NUL", /* '\0': null character */
"SOH", /* ---- start of heading */
"STX", /* ---- start of text */
"ETX", /* ---- end of text */
"EOT", /* ---- end of transmission */
"ENQ", /* ---- enquiry */
"ACK", /* ---- acknowledge(ment) */
"BEL", /* '\a': bell */
"BS", /* '\b': backspace */
"HT", /* '\t': horizontal tab */
"LF", /* '\n': line feed / new line */
"VT", /* '\v': vertical tab */
"FF", /* '\f': form feed */
"CR", /* '\r': carriage ret */
"SO", /* ---- shift out */
"SI", /* ---- shift in */
"DLE", /* ---- data link escape */
"DC1", /* ---- device control 1 / XON */
"DC2", /* ---- device control 2 */
"DC3", /* ---- device control 3 / XOFF */
"DC4", /* ---- device control 4 */
"NAK", /* ---- negative ack. */
"SYN", /* ---- synchronous idle */
"ETB", /* ---- end of trans. blk */
"CAN", /* ---- cancel */
"EM", /* ---- end of medium */
"SUB", /* ---- substitute */
"ESC", /* ---- escape */
"FS", /* ---- file separator */
"GS", /* ---- group separator */
"RS", /* ---- record separator */
"US", /* ---- unit separator */
"SPACE" /* ---- space */
};
char *del_code =
"DEL"; /* ---- delete */
int main( int argc, char *argv[] )
{
int i;
for ( i = 0; i < 33; ++i )
{
printf( "\t%3d 0x%2x: %s\n", i, i, ctrl_code[ i ] );
}
for ( i = 33; i < 127; ++i )
{
printf( "\t%3d 0x%2x: %c\n", i, i, i );
}
printf( "\t%3d 0x%2x: %s\n", 127, 127, del_code );
return EXIT_SUCCESS;
}
(Again, if you're working on a pre-ANSI C compiler, remember to change the main() function declaration to the pre-ANSI K&R style:
int main( argc, argv )
int argc;
char *argv[];
{ ...
}
I think most K&R C compilers should compile it with that change.)
Looking through the code, you probably think you recognize what the ctrl_code[] array is, but look close. It is not a two dimensional array of char. It's an array of char *, and the pointers point to anonymous char arrays of varying length. If we'd written it out with explicit C char array strings, it would look something like this:
char ent00[] = "NUL"; /* '\0': null character */
char ent01[] = "SOH"; /* ---- start of heading */
char ent02[] = "STX"; /* ---- start of text */
...
char ent33[] = "SPACE"; /* ---- space */
char *ctrl_code[] =
{
ent00, ent01, ent02, ... ent33
};
But C takes care of all of this for us, without the nuisance of all the entNN
names.
The advantage of this structure is pretty clear, I think. Well, maybe it's clear.
In many cases, we can save some memory space because each char string does not have to be as long as the longest plus the byte for the trailing NUL.
More importantly, we don't have to check whether we've accidentally clipped off that trailing NUL. (Right?)
(Clear as mud? Well, follow along with me anyway. It does clear up.)
The compiler is free to allocate just enough space for the char array
and its trailing NUL, and to take care of the petty details for us.
All we have to do is remember that It's not really a two dimensional array. It just looks an awful lot like one.
----- Side Note on Memory Usage -----
You may be wondering how much space is actually saved in this particular table by using an array of char * pointers instead of a two-dimensional array of char. It's a good question. Let's calculate it out.
If this array were declared as a two-dimensional array, we'd want the rows
long enough to handle the longest mnemonic plus NUL. The longest mnemonic is
SPACE, so that's 6 bytes:
char ctrl_code[ 33][ 6 ];
Total space is 33 rows times 6 bytes per row, or 198 bytes.
As we've declared it above, it will be 33 times the size of a pointer plus the individual string lengths. If pointers are sixteen bits (16-bit addresses), that's 66 bytes. If pointers are 32 bits (1990s computers, 32-bit addresses), that's double, or 132 bytes.
On modern (64-bit address) computers, that's 8 bytes per address, or 264
bytes, just for the pointers themselves.
For the individual string lengths, there are 19 three-byte mnemonics, 13 two-byte mnemonics, and 1 five-byte mnemonic. Adding in the NUL, that's
19 x 4 + 13 x 3 + 6 == 76 + 39 + 6 == 121
For the various address sizes:
- 16-bit: 66 + 121 == 187 bytes (11 bytes saved)
- 32-bit: 132 + 121 == 253 bytes
- 64-bit: 264 + 121 == 385 bytes
del_code could go either way, independent of the
ctrl_code array. Declared as a pointer to an anonymous array, it
consumes 2 bytes for the pointer (on a 16-bit architecture) and four for the
anonymous array. We really don't need the pointer pointing to it, and
accessing the array directly would use the same syntax. But sometimes you do
things for consistency, and it is not always a bad thing to do so.
So, in this case, we really aren't saving space, unless we're working on a retro 16-bit computer, and even then not much.
The benefit of not having to worry about the trailing NULs is no small benefit, and the extra memory use does not worry us nearly as much on machines where a few hundred bytes are well less than a millionth of the total available memory.
----- End Side Note on Memory Usage -----
The source code itself for this control code table gives us a good table of control codes, for reference, of course. But since it is source code, we can use it to make other tables from it.
Anyway, let's look at the source code. Since the source you copied out is way
up off the screen, refer to it from the file where you copied it while you
read this.
I include SPACE in it for convenience, even though SPACE really isn't classified as a control code by C's libraries, or by the language itself. That's no problem, is it? -- as long as we both remember that I'm playing a small game with semantics.
DEL is way up at the top of the ASCII range, and I don't have anything to
pre-define for the visible character range, so DEL is not in the control code
table. It gets its own named, NUL-terminated char array. Again, I just
have to remember to print it's line out after I've done the rest.
I've declared the traditional counter for for loops, i, and I have one loop that is dedicated to the control codes.
This time, I'm using printf() instead of puts() or my_puts(). One reason is that the previous three projects should have gotten us comfortable with some of the details that you miss when using printf(). Another is that we want numeric and textual formatted output, and we aren't ready to write numeric output routines ourselves, and printf() does numeric output and was designed for formatted output.
A lot of people read printf() as "print file". I forget and read it that way myself from time to time. It's habit that's catching. But it's not what printf() means. printf() means "print formatted".
And that's what it does. The first parameter is a format string. The parameters after the first are what we want formatted.
The format string for the first and third printf()s is this:
"\t%3d 0x%2x: %s\n"
Working through the format --
\t is the tab character. It'll give us a little regular space on the left.
%d is decimal (base ten) integer (not real or fractional) numeric output. %3d
is three columns wide, right-justified. We print the loop counter out here,
because the array of control code mnemonics is arranged so that the code is
the same as the index, and we are using the loop counter as the index.
The space character that comes next is significant. We output it as-is, along with the zero and lower-case x which follow.
%x is hexadecimal numeric output, and %2x is two columns wide, right
justified. (This was a little bit of a mistake. I'll show you how to fix it,
below.) Then we use this format to output the loop counter again, so we can
see the code in hexadecimal.
Then the colon and the following space are output as-is, and %s just outputs
the char array passed in as a string of text. We pass in the mnemonic, and the
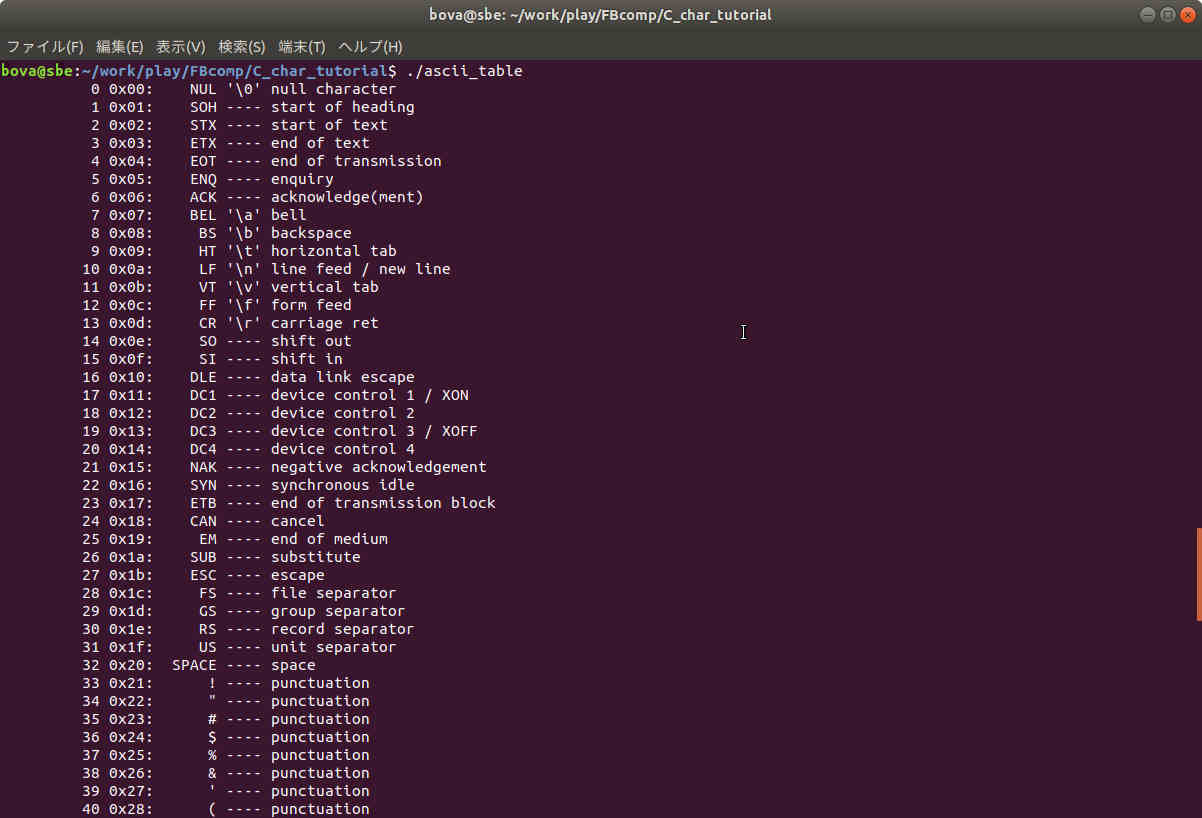
formatted print is done. The output looks like this:
0 0x 0: NUL
1 0x 1: SOH
...
13 0x d: CR
...
31 0x1f: US
32 0x20: SPACE
The second loop has a slightly different format, but the result is adjusted to the first:
"\t%3d 0x%2x: %c\n"
The first two formats are the same. The third is a char format, which outputs the integer given to it as an (ASCII range) character. All three get the loop counter, so we see the character codes in decimal, then in hexadecimal, then the actual character. It looks like this:
33 0x21: !
34 0x22: "
...
...
47 0x2f: /
48 0x30: 0
49 0x31: 1
...
64 0x40: @
65 0x41: A
66 0x42: B
...
125 0x7d: }
126 0x7e: ~
Then the DEL is output with the same format as the other control characters. The loop counter ends at 127 after the visible character range finishes, so we could have used the counter, but we go ahead and pass it the code for DEL as a literal constant.
127 0x7f: DEL
To demonstrate that we have quite a bit of flexibility in output formats, I've
written a bit more involved table generator, and it follows. It gives a few
more examples of ways to use the formatted printing. Also it gives us a
look at the use of struct to organize information:
/* A more involved program to print the ASCII chart,
** as part of a tutorial introduction to C.
** This instance the work of Joel Rees,
** Whatever is innovative is copyright 2021, Joel Matthew Rees.
** Permission granted to modify, compile, and run
** for personal and educational uses.
*/
#include <stdio.h>
#include <stdlib.h>
#include <ctype.h>
struct ctrl_code_s
{
char * mnemonic;
char * c_esc;
char * description;
};
/* reference:
== *nix man command: man ascii
== Also, wikipedia: https://en.wikipedia.org/wiki/ASCII
*/
struct ctrl_code_s ctrl_code[33] =
{
{ "NUL", "'\\0'", "null character" },
{ "SOH", "----", "start of heading" },
{ "STX", "----", "start of text" },
{ "ETX", "----", "end of text" },
{ "EOT", "----", "end of transmission" },
{ "ENQ", "----", "enquiry" },
{ "ACK", "----", "acknowledge(ment)" },
{ "BEL", "'\\a'", "bell" },
{ "BS", "'\\b'", "backspace" },
{ "HT", "'\\t'", "horizontal tab" },
{ "LF", "'\\n'", "line feed / new line" },
{ "VT", "'\\v'", "vertical tab" },
{ "FF", "'\\f'", "form feed" },
{ "CR", "'\\r'", "carriage ret" },
{ "SO", "----", "shift out" },
{ "SI", "----", "shift in" },
{ "DLE", "----", "data link escape" },
{ "DC1", "----", "device control 1 / XON" },
{ "DC2", "----", "device control 2" },
{ "DC3", "----", "device control 3 / XOFF" },
{ "DC4", "----", "device control 4" },
{ "NAK", "----", "negative acknowledgement" },
{ "SYN", "----", "synchronous idle" },
{ "ETB", "----", "end of transmission block" },
{ "CAN", "----", "cancel" },
{ "EM", "----", "end of medium" },
{ "SUB", "----", "substitute" },
{ "ESC", "----", "escape" },
{ "FS", "----", "file separator" },
{ "GS", "----", "group separator" },
{ "RS", "----", "record separator" },
{ "US", "----", "unit separator" },
{ "SPACE", "----", "space" }
};
struct ctrl_code_s del_code =
{ "DEL", "----", "delete" };
char ctrl_format[] = "\t%3d 0x%02x: %6s %s %s\n";
int main( int argc, char *argv[] )
{
int i;
for ( i = 0; i < 33; ++i )
{
printf( ctrl_format, i, i,
ctrl_code[ i ].mnemonic, ctrl_code[ i ].c_esc, ctrl_code[ i ].description );
}
for ( i = 33; i < 127; ++i )
{
printf( "\t%3d 0x%02x: %6c %s %s\n", i, i, i,
isdigit( i ) ? " DEC" : ( isxdigit( i ) ? " HEX" : "----" ),
ispunct( i ) ? "punctuation" : ( isalpha( i ) ? "alphabetic" : "numeric" ) );
}
printf( ctrl_format, 127,127,
del_code.mnemonic, del_code.c_esc, del_code.description );
return EXIT_SUCCESS;
}
(I could have used the first program to output a skeleton source for this one,
but I decided to use regular expressions again to extract the various fields,
instead.)
The ctrl_code_s struct template has three char * fields
-- the mnemonic, the C escape code if there is one, and a more verbal
description from the manual page and from Wikipedia. (I extracted the
initializations from the source of the first one, again, using the regular
expression search-and-replace in gedit.)
The initializations enclose the triplets of anonymous char arrays in curly braces, and we format the source to make it easy to see that the right data goes with the right data. Again, the order of the elements is such that the index of the array of struct ctrl_code_s is the same as the ASCII code.
Some pre-ANSI compilers may not handle this kind of nested initialization. In that case, you may be able to do the initializations without the inner sets of curly braces. It becomes trickier, because such compilers can't help you be sure that the sets are kept together correctly, but it's worth trying. If it doesn't work, you can give up on the array of struct ctrl_code_s, and use three separate arrays.
(If the compiler doesn't nest initializations and you want to use the array of struct ctrl_code_s anyway, you can set up the three separate initialized arrays and then copy the fields into the uninitialized struct ctrl_code_s. It might be an interesting exercise to do, anyway, to help you get a better handle of what a pointer is and what it points to.)
Also, some compilers did not support ternary expressions well. If that's the case with your compiler, try the following for the second loop, instead:
for ( i = 33; i < 127; ++i )
{
char * numeric = "----";
char * char_class = "numeric";
if ( isdigit( i ) )
{
numeric = " DEC";
}
else if ( isxdigit( i ) )
{
numeric = " HEX";
}
if ( ispunct( i ) )
{
char_class = "punctuation";
}
else if ( isalpha( i ) )
{
char_class = "alphabetic";
}
printf( "\t%3d 0x%02x: %6c %s %s\n", i, i, i, numeric, char_class );
}
I've kept the evaluation the same as the ternary expressions, which may help if you're having trouble working those out.
(And if your compiler complains at declaring variables inside nested blocks, you'll need to move the declarations of the variables numeric and char_class up to the main() block where "int i" is declared. But you'll also need to re-initialize them each time through the loop, in the same place they are declared and initialized above.)
One thing you'll notice in the mnemonic field initializations is the
use of the backslash escape character to escape itself. For NUL's escape
sequence, for example, the source code is written
"'\\0'"
What is actually stored in RAM is the single-quoted escape sequence of
backslash followed by the ASCII digit zero:
'\0'
the single quotes acting in the source as ordinary characters within the double-quoted initialization string, but the first backslash still acting as the escape character so you can store control code literals in your code. If we used only one backslash in the initialization for NUL, it would not get the escape sequence, it would get the literal NUL -- a byte of 0.
(You might be interested in what happens when you print out a NUL character.
If you are, give it a try.)
ctrl_code[ 0 ].mnemonic
And, if (for some reason) we wanted the third character of the description of
the horizontal tab, the syntax would be
ctrl_code[ 9 ].description[ 2 ]
Examing the source code and the output should give you some confidence in what
you are seeing.
Again, DEL gets its own struct ctrl_code_s, not in the main ctrl_code array.
This time, I'm showing that the output format is, in fact, just a NUL-terminated char array, by declaring it before I use it and giving it a name:
char ctrl_format[] = "\t%3d 0x%02x: %6s %s %s\n";
Other than fixing the format for the hexadecimal field, it's the same as before, but with more %s fields for added information.
I thought about using the same format for the visible character range, but that gets a bit cluttered, so I gave it it's own format."\t%3d 0x%02x: %6c %s %s\n
The format for the visible range also adds information fields, just to demonstrate the ctype library and one more conditional construct.
I use the first information field to show whether the character is hexadecimal, decimal, or not numeric, using the functions isdigit() and isxdigit() from the ctype standard library.
The parameter to printf() here is a calculated parameter, using the ternary conditional expression,
condition ? true_case_value : false_case_value
The second informational field is also calculated, using the ctype functions ispuncti() and isalpha() called from within the (nested) ternary conditional expression.
And there are no more surprises in the line for DEL.
Compiling it yields no surprises:
----- Side Note on Memory Usage -----
ctrl_code_s is a struct containing three pointer fields. The pointers alone consume 6, 12, or 24 bytes per entry. Multiply that by 34 (to include SPACE and DEL), and there are 204, 408, or 816 bytes in use just for the pointers. The arrays for the first field consume, from the calculations above, 121 + 4 bytes. The next field is 4 bytes plus NUL, five for each one, times 34, makes it 170 bytes.
I used the program itself to add the description strings up. I'll show how later, but the total of the descriptions is 491. The total for all three fields is 786.
Together with the pointers:
- 16-bit: 786 + 204 == 990 bytes
- 32-bit: 786 + 408 == 1194 bytes
- 64-bit: 786 + 816 == 1602 bytes
Each field could be declared as a constant length array of char.
Can you work out how that would affect the size of the table by yourself? It gives a savings of about 300 bytes on 16-bit machines and about 100 on 32-bit machines, with an extra usage of about 300 on 64-bit machines.
Oh, why not now? Here's the code to add at the end of main:
{ int sums[ 3 ] = { 0, 0, 0 };
for ( i = 0; i < 33; ++i )
{ sums[ 0 ] += strlen( ctrl_code[ i ].mnemonic ) + 1;
sums[ 1 ] += strlen( ctrl_code[ i ].c_esc ) + 1;
sums[ 2 ] += strlen( ctrl_code[ i ].description ) + 1;
}
sums[ 0 ] += strlen( del_code.mnemonic ) + 1;
sums[ 1 ] += strlen( del_code.c_esc ) + 1;
sums[ 2 ] += strlen( del_code.description ) + 1;
printf( "mnemonic: %d, c_esc: %d, description: %d\n",
sums[ 0 ], sums[ 1 ], sums[ 2 ] );
printf( "total; %d\n", sums[ 0 ] + sums[ 1 ] + sums[ 2 ] );
printf( "with pointers on this machine; %ld\n",
sums[ 0 ] + sums[ 1 ] + sums[ 2 ] + 34 * sizeof (struct ctrl_code_s) );
}
You'll need to
#include <string.h>
at the top, for strlen().
Be sure to grab the enclosing curly braces. Probably want to change the name of the program, too, while you're at it.
Also, be aware that sizeof is an operator, not a function. There is a very good reason for why I use sizeof and strlen() where I use them, which I will explain later. (Or you can look it up now if you want.)
One more thing to be aware of, compilers will often pad structures in
places that make code faster, so the discussion I give above of memory use is
actually more about minimum memory use.
----- End Side Note on Memory Usage -----
So, now that we have these two programs, what next?
What can you think of to do with these tables, or with the pieces of the language and the libraries that these two programs use?
Try it.
Unicode?
A complete Unicode table would be huge, and, since it has way more than 256
characters in it, it won't fit in the C char type. (Did I mention that
before? This is one reason I insist that char is not actually a
character type.) I hope to take up a partial Unicode table later, although it
might not work with pre-ANSI C compilers and the OSses they run under.
Woops. I forgot about the HTML table. That could be the next project. Why don't you see if you can finish a short program to produce the HTML table for yourself before I can?
[TOC]