[TOC]
I regularly see questions about handling characters in C, regularly enough
that it may be time to write a tutorial on the subject.
What is this character thing and what is the C?
C is a very widely used programming language.
Characters, well, they're a bit hard to pin down, but they have something to
do with the letters we write words in -- A, B, C,
い、ろ、は、イ、ロ、は、色、匂、散、 etc. Without characters, getting
information into and out of computers quickly becomes rather difficult.
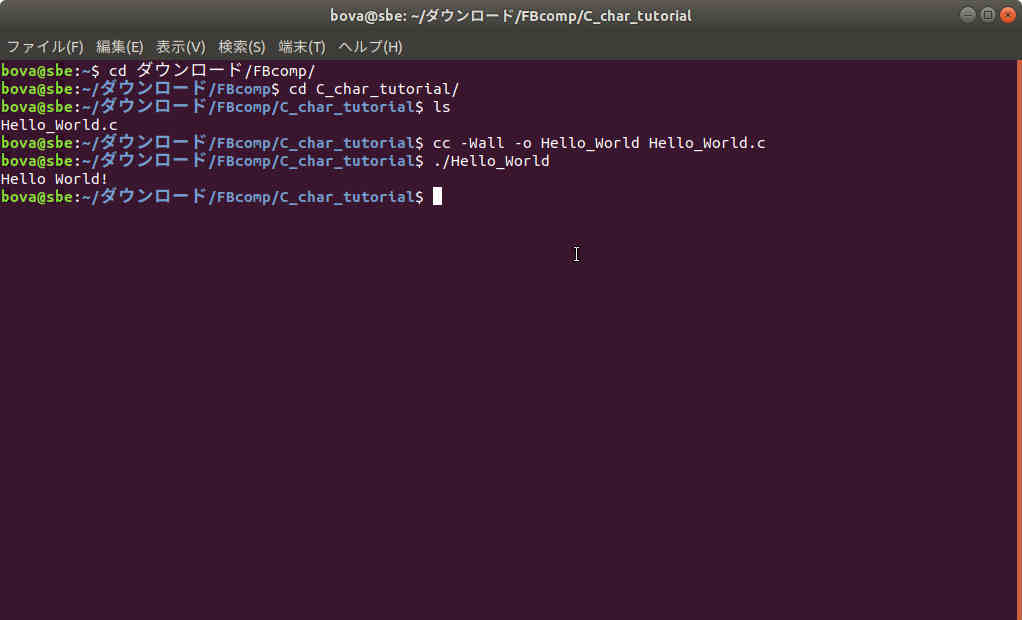
Let's look at the archetype of introductory programs:
/* The archetypical Hello, World!" program.
** This instance the work of Joel Rees,
** but it's to trivial to be copyrightable.
*/
#include <stdio.h>
#include <stdlib.h>
int main( int argc, char *argv[] )
{
puts( "Hello World!"); /* Sure -- puts() works as well as printf(). */
return EXIT_SUCCESS;
}
Recapping and explaining the C programming language elements:
Between the /* and the */ is comment for humans. The compiler
(mostly) ignores it.
The #include statements are there to tell the compiler to invoke interface
definition headers for standard function libraries, standard IO and standard
miscellaneous lib(rary). A linking loader will later link the functions in,
and we don't need to think too deeply about them just now.
The line "int main( int argc, char * argv[] )" tells the compiler that this is
the main() function of the program, that it returns an integer to the
operating system (as main() functions traditionally should), and that it knows
about the command-line variables that inform the program of the number
("argc") of parameters passed in from the OS and the content ("argv") of the
parameters. (We'll look at the command-line parameters soon.)
If you're using a pre-ANSI C compiler, you may need to change the definition of main() as
follows:
int main( argc, argv ) /* You may even need to leave out the parameter names.
*/
int argc;
char ** argv; /* char * argv[] should also
work in most cases. */
{
/* Same code as above comes
here. */
}
For some compilers/operating systems, the system does not provide the parameter
count or array. In such cases, just leave the parameters to main() out
completely. (And I'll explain that later, too.)
Which all sound like technobabble to the beginning C student, but it does
become meaningful at some point.
For now, main() is where your program starts. (Essentially.)
------ Side Note on Code Formatting ------
The curly braces ("{}") define a block of code, and the fact that they come
immediately after the line that says this is main(), with no punctuation
between, tells the compiler that the stuff between is what the program should
do.
A note on those curly braces. Some -- well, a lot of -- people think that the
opening brace belongs on the line above where I've put it, like this:
int main( int argc, char *argv[] ) {
It's wrong, but that's their preferences and their business. The whole world
can be wrong sometimes. In this tutorial, I'm putting the open brace down
where I and you can see it.
(You'll need to get used to both ways, and some variations of both, if you try
to make a living programming. Don't fuss over it. And if it's easier for you
to see the other way, when you copy the programs out of the tutorial put them
where it's easier for you to see.)
------ End Side Note on Code Formatting ------
So the block of code that defines what this program does consists of two lines. The second of
those tells the program to pass back to the operating system a code that tells
the OS that the program exited with success.
The meat of the program is the line that puts the string, "Hello, World!" on
the output device, which is usually a terminal window these days.
If you've seen the Hello World program in C before, you may have seen it done
with printf() instead of puts(). I chose puts() here because it's a much
simpler function to explain. I mean, I've already explained it.
Now I can focus on the string of characters in this program. Not the string of
characters which comprises the source code of the program, but the string
which the program, when compiled and run, should output, the five letters 'H',
'e', 'l', 'l', and 'o', the space which follows, the five letters 'W', 'o',
'r', 'l', and 'd', and the punctuation character which follows, the
exclamation mark. (Or, the exclamation point in some parts of the world.):
Hello World!
This is a string of characters, as we say. And puts() puts them out on the
output device, whatever the output device is. Here's a sample output when run
on a Linux OS, in a terminal emulator:
Now this terminal screen is not all that obvious. In the modern world,
you would have bells and whistles and dancing assistants, explaining what the
picture shows, and the picture would be a video instead of a still shot. So
I'll show you the dancing assistant's script:
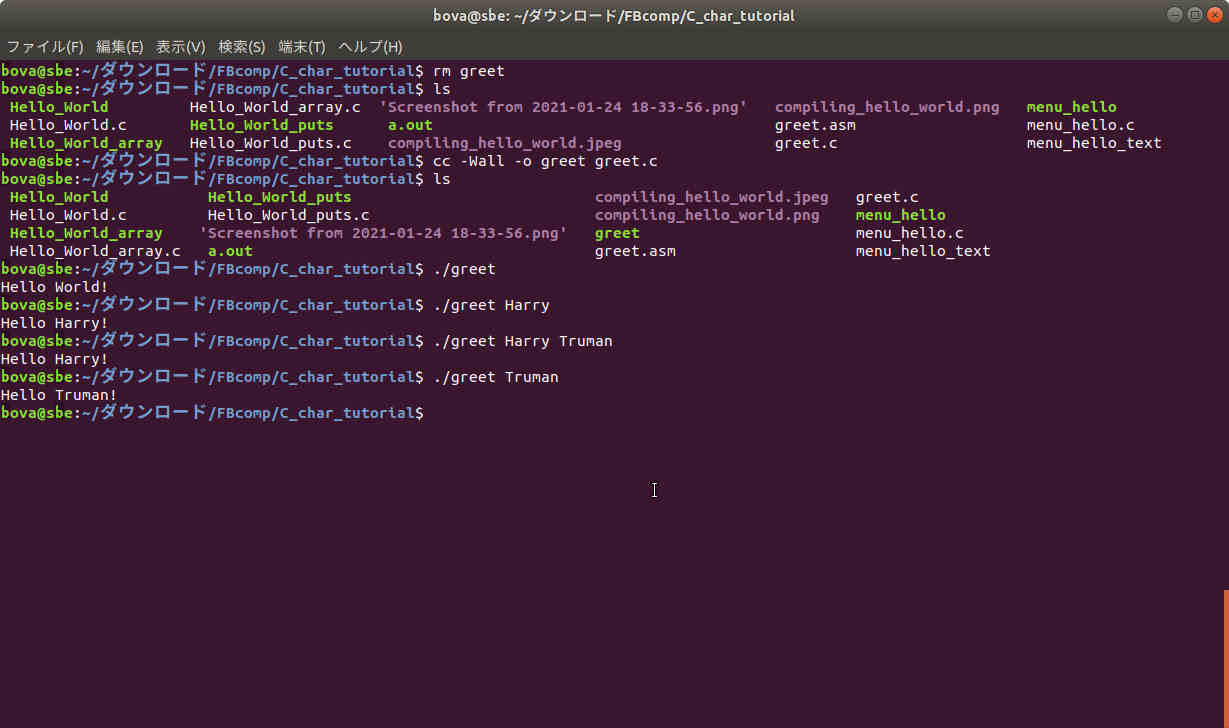
In the above screenshot on a typical computer running Ubuntu, you can see
me
- moving to the directory where the source code is stored:
cd ダウロード/FBcomp/
("cd" stands for "change directory".)
- listing the contents of the directory:
ls
("ls" stands for "list". There is only one file, the source file Hello_World.c
, and you see it listed in the line below the command. In MSWindows command
line shells, it would be "dir".)
- issuing the compile command:
cc -Wall -o Hello_World Hello_World.c
("cc" stands for "C compile".
"-Wall" stands for "Warn all warnings".
"-o Hello_World" means "name the executable object file for the program 'Hello_World'.".
"Hello_World.c" is the name of the file containing the source code. It
occurs to me now that using a different name for the source and object files
would have been a little less confusing.)
- and issuing the command to run the program:
./Hello_World
("./" in a *nix shell says look only in the current local directory.) And you
can see the output after the last command:
Hello World!
Hmm. I could do a video of this. It's something to think about. But until I
have the time, I'll hope you can follow this well enough.
------ Side Note on Getting a Compiler ------
To actually compile this and run the programs, you'll need a compiler and some
system software that supports it.
*nix (LInux and BSD OSses, et. al., and Plan 9):
If you are on a Linux or BSD or similar libre operating system, you'll have a
package manager that will help you install the compiler tools (if they are not
already installed), and the web site for your OS distribution (vendor) will
have pages on how to check if they are installed, and how to install them if
they aren't.
*Mac:
If you're on a Mac, I understand the current official thing is to get XCode
from the App store. It looks like Apple will push you to learn Swift, which I
suppose is okay, but I can't help you with that. XCode should allow you to
compile C programs with clang. Clang is like gnu cc, but, instead of typing
the command "cc" like I show above, you type the command "clang". (Clang can
also be used on Linux, and gcc can also be used on Mac, but that requires some
setup, and is a topic for another day.)
*Microsoft Windows:
Microsoft's Visual Studio will only continue to push you to remain in
Microsoft's world, so I don't recommend that. The Hello World for that world
is different from what I describe here, and will send you jumping through
hoops to open a window to display it in, which is fine for opening a window
just to display a string in, but doesn't really help you start understanding
what a string is or what is really happening underneath or how to go to the
next step.
Microsoft also has a Windows Subsystem for Linux, which allows you to install
full Linux distributions in your MSWindows OS (apparently to run under
emulation). I have not used it. I can't recommend either for or against it.
But layering more layers over reality never helps learn about reality. Still,
if you just want to get your toes wet, it might be the thing for you.
*Cygwin:
Cygwin allows you to install the Gnu C Compiler tools on MSWindows computers,
along with certain other software from the libre software world. If you must run
MSWindows, I think I recommend Cygwin.
Instructions for downloading and installing Cygwin on MSWindows can be found
at
Get the gnu C compiler and basic libraries using the installer, after you
check the checksum to make sure it downloaded safely, and, if you have gnupg
or other way to check the fingerprint, check the fingerprint so you know it
came from the right place..
*Android:
There are a several apps to install a C compiler and walled runtime
environment on Android. I have not used any of them, can't recommend either
for against, but the layers principle applies. And they take up space you may
need for other things. (Space is the primary reason I have not used any of
them.) But they may be good for getting your feet wet.
There are also partial Linux systems (like NoRoot) that can allow more than
just compilers to be installed, but don't allow full access to the phone. (The
walls do help keep the phone somewhat safe.) You'll need to search for an app
that is compatible with your phone and Android OS, however.
I have heard that recent Android Phones can officially (by Google approved
methods) be turned into full Linux computers, but that seems to be more rumor
than fact.
*Downloading Linux and BSD OSses:
Instructions for downloading and installing a full Linux or BSD system to
replace or dual-boot with your MSWindows OS can be found at their respective
sites. As I mentioned above, once you have one of those installed, getting the
compiler and other tools is simply a matter of running the package manager and
telling it to install the tools.
(I'm currently running Ubuntu on an older Panasonic Let's Note with 4G
RAM, using about 100G of the internal SSD.)
Some OSses I have a bit of experience with include
There are other distributions of both LInux and BSD OSses, such as Dragonfly
BSD, Arch Linux, OpenSUSE, Fedora (Red Hat), CentOS, Mint OS, and so forth.
*Others:
There are other options similar to the BSD distributions, such as Minix, Plan
9 (Inferno), and Open Solaris. Your web search engine should find relevant
information quickly.
If you are using an older (classic) Macintosh, Apple's Macintosh Programmer's
Workbench (MPW) has a good compiler and a fun, if quirky by today's standards,
workbench environment. Codewarrior for the Mac was also good, if quirky in other ways.
Radio Shack/Tandy's venerable 8-bit Color Computer had OS-9/6809, for which a
compiler was available from Microware. (Not Microsoft, okay?) It was a
pre-ANSI compiler. Other ANSI compatible and pre-ANSI compilers were available
for all that gear that is now retro gear, and you can often find those
compilers to download. I'll discuss pre-ANSI (K&R) C syntax, but I won't
try to deal with Small C.
*Trusting an Alternate OS:
If you are wondering how you can trust one of these alternate OSses, I talk
about that a little
here:
https://defining-computers.blogspot.com/2019/05/analyzing-mechanized-trust.html
Some of what I say there, I'm not completely sure is universal, but if you have questions, that rant
should give you some good pointers to start researching your questions.
------ End Side Note on Getting a Compiler ------
Back to the Hello World program.
It's a simple program. It also invites some misunderstanding, which is the
real reason for this post. While you read this, keep the text editor window
where you copied and pasted the source open for reference.
I am now going to tell you something that may have you thinking I'm telling
you lies. But Kernighan and Ritchie explain it as well, in their book
The C Programming Language. I'm just going to try to make it more
obvious.
The programming language C does not inherently support strings of text. No
real character type in the language proper, no real character string type, either.
Okay, I said it.
(The support is indirect, through library functions, and is not nearly
as complete in the standard libraries as you want to think.)
In the program, collecting the "Hello World!" between the quotes into a byte
array and terminating it with a NUL byte is, uhm, well, it's part of C, but it
isn't.
To explain that somewhat carefully, let's do a few alternate versions of the Hello
World program:
/* Not so typical Hello, World!" program.
** This instance the work of Joel Rees,
** Copyright 2021 Joel Matthew Rees.
** Permission granted to modify, compile, and run
** for personal and educational uses.
*/
#include <stdio.h>
#include <stdlib.h>
char greeting1[ 32 ] = "Sekai yo! Konnichiwa!";
/* This could be done on a single line.
-- I'm doing it this way for effect.
*/
char greeting2[ 16 ] =
{
'H',
'o',
'l',
'a',
' ',
'M',
'u',
'n',
'd',
'o',
'!',
'\0', /* <= Look! It's a NUL! */
0 /* <= Look! It's another NUL! */
};
int main( int argc, char *argv[] )
{
puts( "Hello World!"); /* Sure -- puts() works as well as printf(). */
puts( greeting1 );
puts( greeting2 );
return EXIT_SUCCESS;
}
You can change that for pre-ANSI compilers as described above.
Several questions should come to mind.
One, why do I use Rōmaji instead of kana or Kanji in the Japanese, and where
is the leading inverted exclamation mark in the Spanish?
I'll get to that in a bit. Maybe in another post.
The other, why do I put explicit NUL bytes on the end of the Spanish version?
Right? Those were the two most obvious questions, right?
No?
Okay, let's work through your questions.
The string that I might have named greeting0, "Hello World!", is automatically
collected in an array like greeting1 and greeting2, but not given a name that
the programmer can use.
It's anonymous.
(If the same identical string occurs elsewhere in the same file, modern
compilers will recognize that and only store it once -- unless you tell them
not to. Older compilers may not search for identical strings, and just store
another copy. But the string doesn't have a name that the C program can
directly use.)
Other than that, the three greetings strings are all treated exactly the same
way. They are collected as arrays of char, and a trailing 0 (NUL) terminator
byte is attached.
(cough.)
Well, sort of. If I had declared them without size, ..., oh, hang on. No, we
won't go there quite yet.
Oh. The size. I guess we do need to go there.
So, no, not quite exactly the same. The anonymous string is allocated enough bytes for
the text and the trailing NUL (and maybe some extra, at the discretion of the
compiler).
The other two are allocated the number of bytes that the source specifies,
thirty-two for greeting1 and sixteen for greeting2 (and maybe some extra, at
the discretion of the compiler). And, if there is enough room after the text
is stored, the rest of the array is filled with zeroes, effectively putting at
least one NUL terminator byte at the end. But only if there is enough
room.
Will the compiler complain if you've declared a size too small for the text
specified?
It should. Usually. I mean, yes. Maybe. Usually.
Which is why, when you explicitly declare strings, you usually declare strings
like this:
char greeting1prime[] = "Sekai yo! Konnichiwa!";
Or like this:
char * greeting3prime = "Bonjour le monde!";
Here, greeting1prime is an array of bytes like greeting1, but the size
allocated is enough bytes for the string plus the trailing NUL (plus extra, if
the compiler wants to).
On the other hand, greeting3prime is a pointer to a byte, initialized with the
address of the anonymously allocated, NUL terminated array "Bonjour le
monde!". In other words, in addition to the string in greeting3prime's case,
you've declared a variable of type
char *
which is a byte pointer -- a variable. You can change what it points to. You
can even lose what it was pointing to, if you're not careful.
Hmm.
Before we go any further, let me explain something.
C has no native character type.
Again, you're doubting my sanity. I know you are. This whole post is a
discussion of characters in C, right?
Not yet. Time for a little history. (This is definitely not an aside.)
Back in the 1970s, when Kernighan and Ritchie and some of their coworkers were
playing around with BCPL and the early versions of C, we didn't know nearly as
much about how to deal with text in computers as we know now. (And there's still a lot we need to learn.)
Even the size of a byte in a computer was not set. Some had 6-bit bytes, some
had 8-bit bytes, and a few had 9-bit bytes. Other sizes also existed, look
them up if you want.
Nowadays, we can be sort-of comfortable thinking of a byte as 8 bits. But a
byte now is (usually) defined as the smallest addressable unit of memory in a
computer.
Which is precisely what C defines the char type as. This was something of a
mistake. The type should really have been called byte.
You can alias the char type to byte with
typedef char byte;
Why did the conflation occur? Glad you asked. (You did ask, I hope.)
Back then, in the western world, we didn't really know much about eastern
languages, so we didn't really consider them.
Western languages all used (as we thought) less than 100 characters, and even
Japanese had the kana, of which there are only around 50 (depending on what's
included).
And computers were beginning to standardize on 8-bit bytes
We assumed that Kanji were built in some orderly manner from smaller parts,
and that those parts would number less than 250, so that they could also be
encoded in bytes.
And we really didn't think about a single encoding that would encompass all
languages, like Unicode. 256 was just too much a magical number to ignore.
256 is still a magical number, but we now know that even English actually
needs more characters than that. (Some members of the computer typesetting
industry of the early 1970s knew that we needed more than 256, but they
weren't writing operating systems and programming languages.)
And, anyway, a typeface with more than 256 characters was known to need more
computing power than an ordinary office could afford. (The 68000 overcame that
barrier, but that was several years after the early K&R C had been defined.)
And that's the simplified version of how characters were conflated with bytes -- a
bit historically incomplete, but good enough to help us think beyond the names of types.
char in C is an integer type. It can be either signed or unsigned, according
to the what the C compiler engineers think works best for a particular family
of computers.
And that should be enough for an introduction to characters in C. No, wait. One
more version of Hello World! --
/* A non-typical Hello, World!" program.
** This instance the work of Joel Rees.
** Copyright 2021 Joel Matthew Rees.
** Permission granted to modify, compile, and run
** for personal and educational use.
*/
#include <stdio.h>
#include <stdlib.h>
/* Implementing our very own puts():
*/
void my_puts( char * string )
{
int i;
for ( i = 0; string[ i ] != '\0'; ++i )
{
putchar( string[ i ] );
}
putchar( '\n' );
}
char greeting1[ 32 ] = "Sekai yo! Konnichiwa!";
/* This could be done on a single line.
-- I'm doing it this way for effect.
*/
char greeting2[ 16 ] =
{
'H',
'o',
'l',
'a',
' ',
'M',
'u',
'n',
'd',
'o',
'!',
'\0', /* We only need one terminator,
** but even this isn't really necessary here
** because we specify a large enough size.
*/
};
char * greeting3 = "Bonjour le monde!";
char greeting4[] = "Hallo Welt!";
int main( int argc, char *argv[] )
{
my_puts( "Hello World!"); /* Sure -- puts() works as well as printf(). */
my_puts( greeting1 );
my_puts( greeting2 );
my_puts( greeting3 );
my_puts( greeting4 );
return EXIT_SUCCESS;
}
For pre-ANSI C compilers, change main() as described above, and change my_puts() as follows:
void my_puts( string )
char * string;
{
/* Code that goes here is the same. */
}
A few things I didn't mention before --
Double quotes are for strings.
(Well, they're for telling C to automatically collect the text into a char
array, and to terminate the array with a NUL if the size isn't specified as
just big enough for the text without the NUL. Try that yourself and see what
happens, by the way. Something like
char fluke[ 15 ] = "This is a test.";
What did it do when you tried to puts( fluke )?)
The single quotes we used in several places are for individual characters, not for strings.
(In some compilers, you can actually pack multiple characters in between the
single quotes, but I'm not going to try to confuse you by telling you that.
Okay? You didn't hear me say that. Okay? Good. You don't want to know what
that does in relation to byte order, in particular. ;))
So, 'A' is a single capital A.
You saw that '\0' is shorthand for a NUL byte, eight bits of zero. Well, zero
in eight bits. (No matter how wide it is, zero is still zero, in any byte
order, thank heavens.)
And you saw in our third version, that '\n' is shorthand for a newline
character.
Oh, and "void" is (among other things) for telling the compiler that a
particular function doesn't have a return value. Also, control returns from a
function at the trailing brace if there is no explicit return.
And you might have noticed, in our my_puts(), that you can use a character
pointer variable as if it were the name of an array in many cases. (There are
other ways to write my_puts(), but we won't go there quite yet, either.)
I have other things to do tonight, so that's it for now.
It's your turn to think of things you can do with this. Explore. Get results you don't expect. Get a copy of the Kernighan & Ritchie's The C Programming Language if you don't already have one, or look it up on the web and figure out why.
(I may or may not write a follow-up to this sometime soon.)
The next step in this tutorial is ready, now. We'll tell the computer whom to greet.
[TOC]